前作:PyNet: Use NumPy to build neuron network。在那里我们基于求导规则实现了全连接网络。在这里,我们向当今的深度学习框架看齐,实现属于自己的DL框架。
库地址:https://github.com/Kaslanarian/PyDyNet.
Overview
PyDyNet(Python Dynamic network)也是纯NumPy实现的神经网络,语法受PyTorch的启发,主体框架:
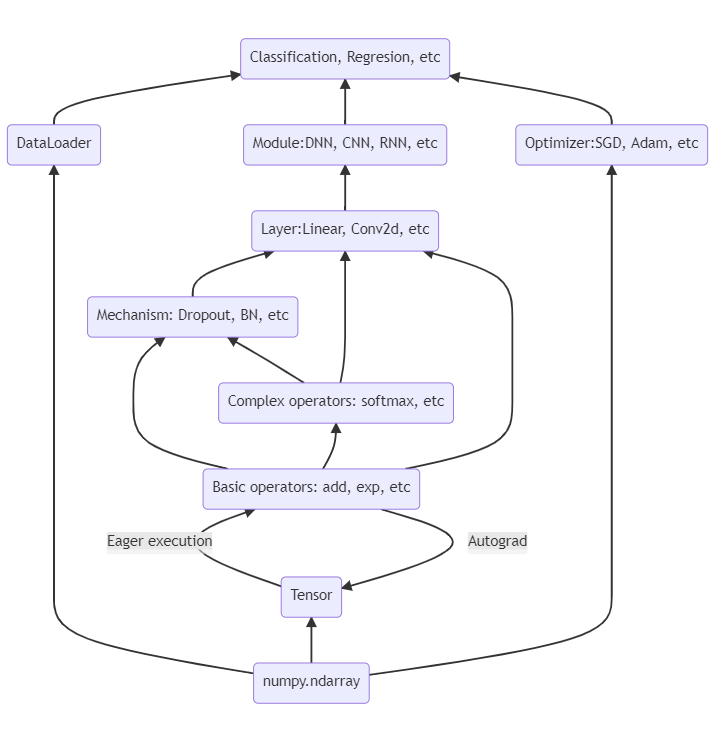
我们实现了:
-
将NumPy数组包装成具有梯度等信息的张量(Tensor):
from tensor import Tensor x = Tensor(1., requires_grad=True) print(x.data) # 1. print(x.ndim, x.shape, x.is_leaf) # 0, (), True -
将NumPy数组的计算(包括数学运算、切片、形状变换等)抽象成基础算子,并对部分运算加以重载:
from tensor import Tensor import functional as F x = Tensor([1, 2, 3]) y = F.exp(x) + x z = F.sum(x) print(z.data) # 36.192... -
手动编写基础算子的梯度,实现和PyTorch相同的动态图自动微分机制,从而实现反向传播
from tensor import Tensor import functional as F x = Tensor([1, 2, 3], requires_grad=True) y = F.log(x) + x z = F.sum(y) z.backward() print(x.grad) # [2., 1.5, 1.33333333] -
基于基础算子实现更高级的算子,它们不再需要手动编写导数:
def simple_sigmoid(x: Tensor): return 1 / (1 + exp(-x)) -
实现了Mudule、各种Layer和损失函数,从而我们可以像下面这样定义神经网络,损失函数项:
import nn import functional as F n_input = 64 n_hidden = 128 n_output = 10 class Net(nn.Module): def __init__(self) -> None: super().__init__() self.fc1 = nn.Linear(n_input, n_hidden) self.fc2 = nn.Linear(n_hidden, n_output) def forward(self, x): x = self.fc1(x) x = F.sigmoid(x) return self.fc2(x) net = Net() loss = nn.CrossEntropyLoss() l = loss(net(X), y) l.backward() -
实现了多种优化器(
optimizer.py),以及数据分批的接口(dataloader.py),从而实现神经网络的训练;其中优化器和PyTorch一样支持权值衰减,即正则化; -
Dropout机制,Batch Normalization机制,以及将网络划分成训练阶段和评估阶段;
-
基于im2col高效实现Conv1d, Conv2d, max_pool1d和max_pool2d,从而实现CNN;
-
支持多层的单向RNN,LSTM和GRU。
Example
examples中是一些例子,都能在上面提供的链接中找到。
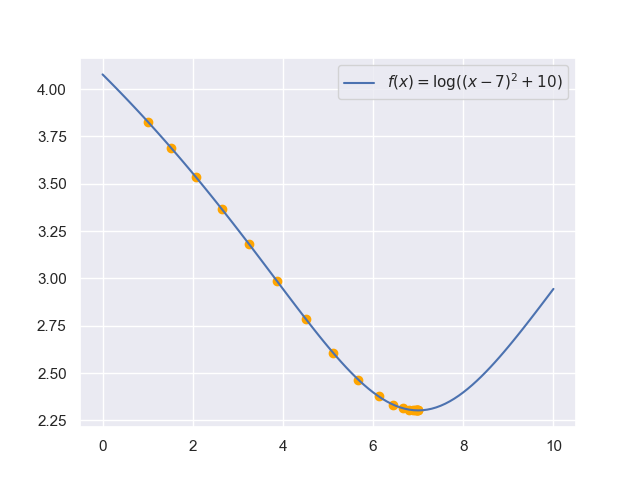
AutoDiff
autodiff.py利用自动微分,对一个凸函数进行梯度下降:
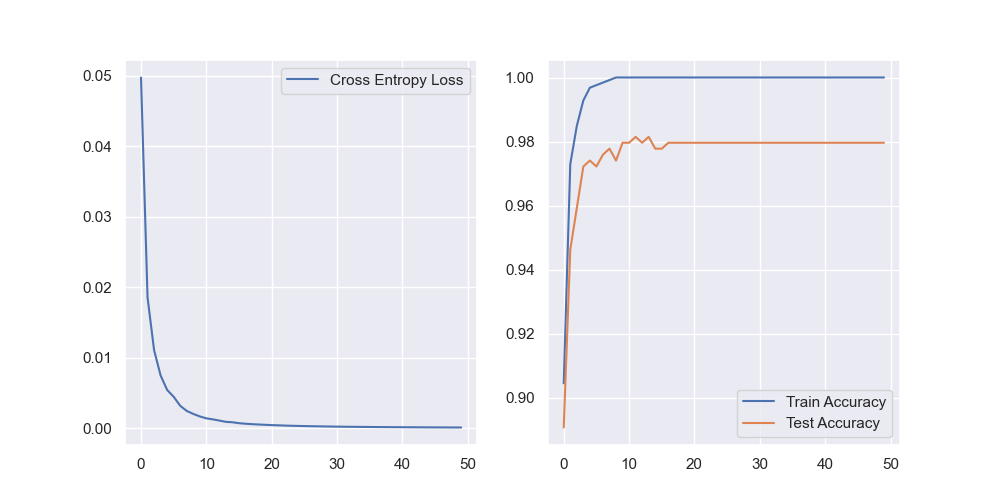
DNN
DNN.py使用全连接网络对sklearn提供的数字数据集进行分类,训练参数
- 网络结构:Linear(64->64) + Sigmoid + Linear(64->10);
- 损失函数:Cross Entropy Loss;
- 优化器:Adam(lr=0.01);
- 训练轮次:50;
- 批大小(Batch size):32.
训练损失,训练准确率和测试准确率:
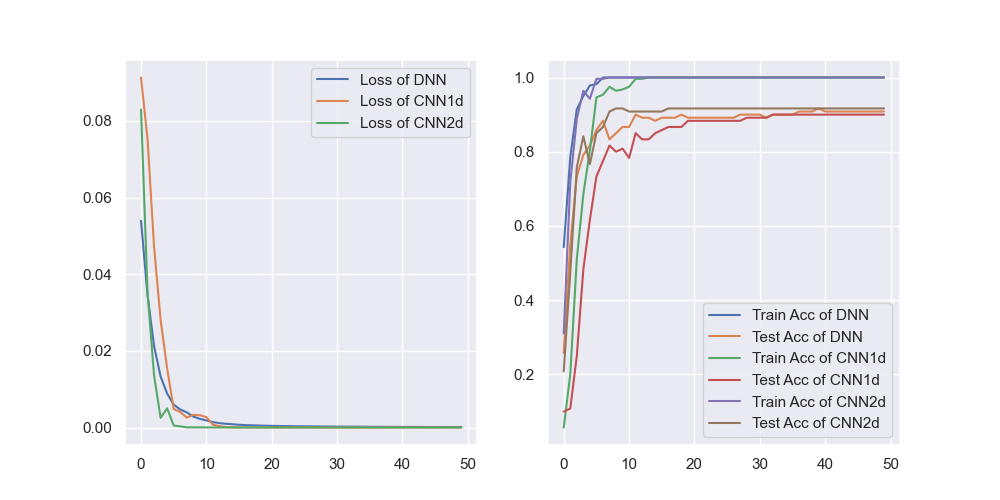
CNN
CNN.py使用三种网络对fetch_olivetti_faces人脸(64×64)数据集进行分类并进行性能对比:
- Linear + Sigmoid + Linear;
- Conv1d + MaxPool1d + Linear + ReLU + Linear;
- Conv2d + MaxPool2d + Linear + ReLU + Linear.
其余参数相同:
- 损失函数:Cross Entropy Loss;
- 优化器:Adam(lr=0.01);
- 训练轮次:50;
- 批大小(Batch size):32.
学习效果对比:
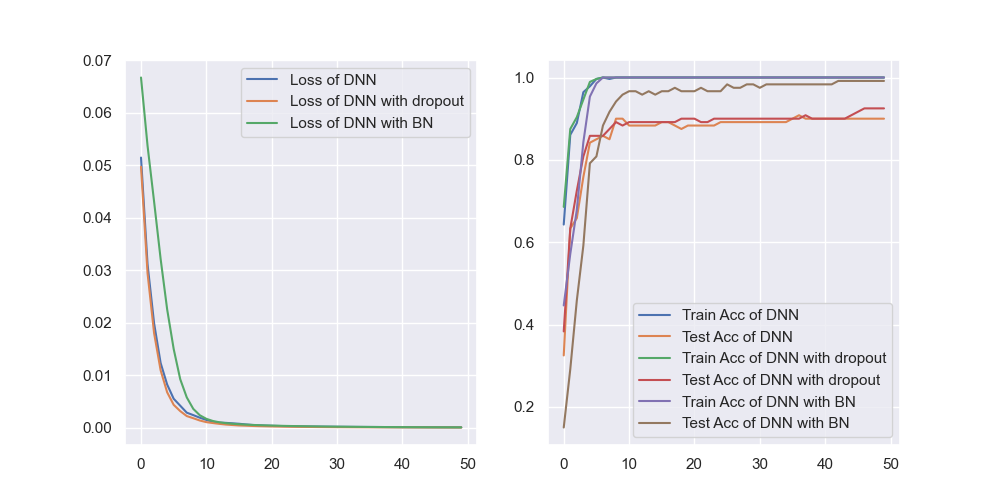
Droput & BN
dropout_BN.py使用三种网络对fetch_olivetti_faces人脸(64×64)数据集进行分类并进行性能对比:
- Linear + Sigmoid + Linear;
- Linear + Dropout(0.05) + Sigmoid + Linear;
- Linear + BN + Sigmoid + Linear.
其余参数相同:
- 损失函数:Cross Entropy Loss;
- 优化器:Adam(lr=0.01);
- 训练轮次:50;
- 批大小(Batch size):32.
学习效果对比:
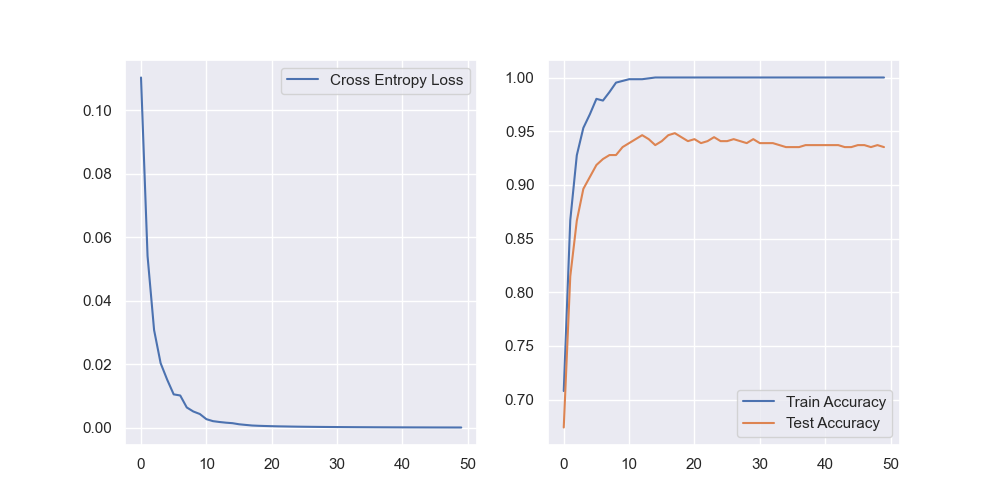
RNN
RNN.py中是一个用GRU对sklearn的数字图片数据集进行分类,由于不是时序数据,效果一般,而且会过拟合:
目前RNN部分的模块还在开发中,包括扩展到双向,引入Attention机制等。
结语
当笔者第一次接触到Neural Network的时候,便一直有实现一个深度学习框架的想法,囿于自身的能力不足迟迟未能实现。一个月才下定决心写一个这样的东西,到今天才算写出点样子出来。期间打翻重做了两次,一是因为把框架写成了静态图,二是没考虑到算子的参数问题,终于还是向PyTorch折腰,模仿了不少它的语法。笔者在后面会陆续写一些文章,着重介绍其中的实现技巧和神经网络相关知识。
当然我们之前已经做了一些前置工作和准备了,这里小列一下: