原文:https://www.jmlr.org/papers/volume9/fan08a/fan08a.pdf
摘要
LIBLINEAR是一个用于大规模线性分类的开源库,它支持逻辑回归和线性支持向量机。文章的作者团队为用户和开发人员提供易于使用的命令行工具和库调用。初学者和高级用户都可以阅读其全面的文档。实验表明,LIBLINEAR在大稀疏数据集上是非常有效的。
引言
解决大规模分类问题在文本分类等许多应用中都是至关重要的。线性分类已成为处理面向大量数据和特征数的大规模稀疏数据的方法中,最有前景的学习技术之一。LIBLINEAR作为一个易于使用的工具就是被用来处理这样的数据。它可以求解这些优化问题:
- 带L2正则化的逻辑回归(LR);
- L2损失的线性支持向量机(L2-SVM);
- L1损失的线性支持向量机(L1-SVM).
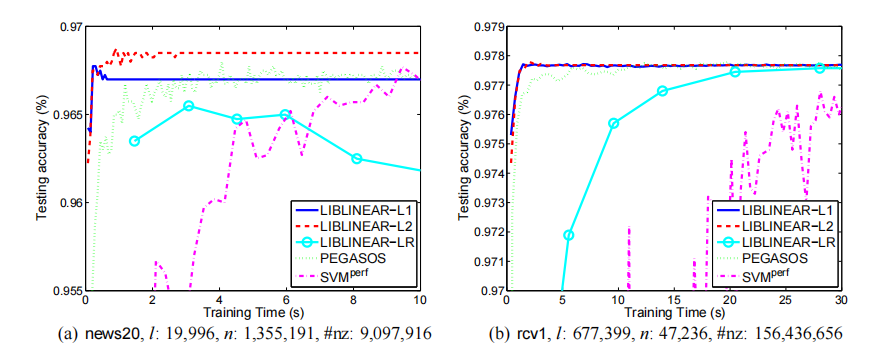
LIBLINEAR的一个特点就是善于处理大规模数据,比如一个60000条样本的文本分类问题,LIBSVM需要几个小时去完成,而LIBLINEAR只需要几秒。此外,LIBLINEAR的性能可以媲美甚至超越当时很优秀的线性分类器软件,比如Pegasos,SVM$^{\text{perf}}$。
线性分类问题
给定带标签数据集$D=\{(\pmb x_i,y_i)\},i=1,\cdots,l,\pmb x_i\in R^n,y_i\in\{-1,+1\}$,LIBLINEAR可以解决下面的无约束优化问题:
\[\min_{\pmb{w}}\quad\frac12\pmb w^T\pmb w+C\sum_{i=1}^l\xi(\pmb w;\pmb x_i,y_i)\]$C$为惩罚参数。其中损失函数$\xi$不同,诱导出不同的优化问题:
-
L1-SVM的损失函数是Hinge loss:
\[\xi(\pmb w;\pmb x_i,y_i)=\max(1-y_i\pmb w^T\pmb x_i,0)\] -
L2-SVM的损失函数是Hinge loss的平方:
\[\xi(\pmb w;\pmb x_i,y_i)=\max(1-y_i\pmb w^T\pmb x_i,0)^2\] -
逻辑回归的损失函数是
\[\xi(\pmb w;\pmb x_i,y_i)=\log(1+\exp(-y_i\pmb w^T\pmb x_i))\]
在这里,判别函数的形式是
\[f(\pmb x_i)=\pmb w^T\pmb x_i\]但实际上我们看到更多的是
\[f(\pmb x_i)=\pmb w^T\pmb x_i+b\]LIBLINEAR考虑到了这一点,如果用户想要的是后一种形式,它会对数据集和参数进行增广:
\[\begin{aligned} \pmb w^T&\gets [\pmb w^T,b]\\ \pmb x_i^T&\gets [\pmb x_i^T,B]\\ \end{aligned}\]其中$B$是由用户指定的常数。
LIBLINEAR使用坐标下降法来解L1-SVM和L2-SVM问题,对于LR和L2-SVM问题,则是用信任域的牛顿法来解决。
LIBLINEAR软件包
LIBLINEAR的设计受到了LIBSVM的启发,包括库和命令行工具,所以两者的使用方式类似。但两种软件包下生成的模型十分不同,比如LIBLINEAR会在模型文件中存储$\pmb w$,而LIBSVM则不会。因此LIBLINEAR和LIBSVM没有且没必要兼容。
LIBLINEAR主要的设计原则是使整个程序包尽可能简单,同时使源代码易于阅读和维护。其中的文件可以划分为源文件、预构建的二进制文件、文档和语言绑定。所有的源代码都遵循C/C++标准,并且不依赖于外部库。因此LIBLINEAR几乎可以在每个平台上运行。它提供了一个简单的生成文件来从源代码中编译程序包。对于Windows用户,我们包括了预构建的二进制文件。
除了原始的C++平台,LIBLINEAR还支持:
- Python;
- Matlab;
- Octave.
性能对比
文章的实验部分针对两个数据集,在相同的训练时间下,将LIBLINEAR中的L1-SVM、L2-SVM和LR模型的性能(分类准确率)与之前的软件包,PEGASOS和SVM$^\text{perf}$进行对比:
阅读感想
在导师的要求下,继LIBSVM后,笔者开始阅读LIBLINEAR的源码。笔者从论文开始读起,重点比较LIBLINEAR和LIBSVM间的差别。阅读完文章后,笔者基于之前LIBSVM源码的阅读总结出下面几种区别:
| 区别 | LIBSVM | LIBLINEAR |
|---|---|---|
| 场景 | 一般的分类、回归任务 | 大规模,耗时的分类、回归任务 |
| 模型 | 核函数使解决非线性问题成为可能 | 模型都是线性的 |
| 数据 | 数据量一般,特征不多 | 数据量大,多特征,且稀疏 |
| 算法 | SMO算法 | 坐标下降、牛顿法 |