在之前的文献解读中,我们介绍了FESL这一学习范式,它通过一个很短的重叠区实现模型复用,从特征空间$S_1$到不相交特征空间$S_2$进行在线学习,然而这已经是2017年的成果了。

在这里,我们将介绍该范式的最新成果,发表在2022年的ACM Multimedia上的Online Deep Learning from Doubly-Streaming Data。作者(作者之一就是上一篇文章的一作)认为当两个特征空间的关系很复杂,比如多媒体数据场景,从一个很短的重叠时间区间来学习它们之间的关系是不现实的。因此,作者提出OLD$^3$S范式,它通过一个共享的潜在子空间来总结新旧特征空间的信息,建立一个中间特征映射关系,这是通过一个变分自编码器(VAE)去实现的。此外,考虑到当VAE太深时,它将不适合在线场景,因此本文使用了ODL方法来充分利用神经网络各层的信息。
Problem Statement
本文面对的还是FESL的场景:
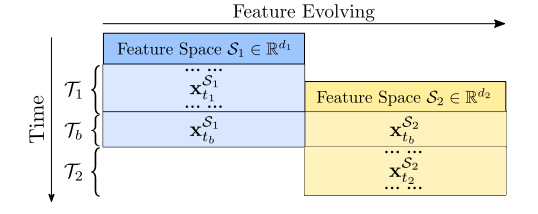
注意这里$\mathcal{T}_b$是一个独立的时间区间,而不是$\mathcal{T}_1$的子集。
Opportunities and Challenges
作者讲述了为什么他当年提出的FESL不能用于现在的多媒体数据:
-
处理多媒体数据需要深度神经网络,然而在线学习场景中深度网络收敛慢将引发很大的遗憾。作者用CIFAR数据集做了下面的实验,观察不同深度网络的收敛速率:
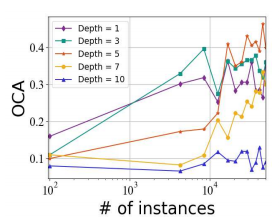
其中OCA意为在线分类准确率。我们发现深度为10的网络甚至不能收敛。
-
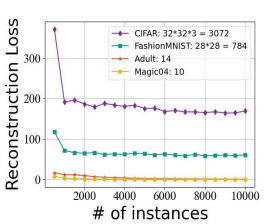
在较短的重叠时间范围内很难学习复杂的重建映射。$\mathcal{T}_b$很短这种约束阻碍了一些看似合理的方法,例如在线迁移学习和领域自适应,以很好地工作,因为它们都需要一个足够长的重叠阶段来对齐进化前和进化后的特征。作者又做了一个小实验以验证:数据维数越高,线性映射捕获的特征关系就越差。
Thought
对于第二个挑战的应对:尝试发现特征空间$\mathcal{S}_1$和$\mathcal S_2$对应的一个共享的潜在子空间。子空间的学习在$\mathcal{T}_1$阶段就可以进行,$\mathcal{T}_b$阶段的任务是将它与$\mathcal{S}_2$的特征子空间对齐,这是通过变分推断去实现的。对$\mathcal{S}_1$数据的建模:
\[Q(\text z_{t_1}^{\mathcal{S}_1}\vert \text{x}_{t_1},t_1=1,\cdots,T_1)=\prod_{i=1}^z\mathcal{N}(\text z_i^{\mathcal{S}_1}\vert\mu_i^{\mathcal{S}_1},(\sigma_i^{\mathcal{S}_1})^2)\]其中变分编码$\text z^{\mathcal{S}_1}\in\mathbb{R}^{z}$是从多元高斯分布采样得来,作为$\mathcal{S}_1$空间数据的压缩表示。之后在$\mathcal{T}_b$重叠期,一个新的变分编码$\text z^{\mathcal{S}_2}\in\mathbb{R}^z$是$\mathcal{S}_2$空间数据的压缩表示,形式和上式相同。我们强制从两个特征空间得到的变分编码分布,也就是两个多元高斯分布相同,使得$\mathcal{S}_1$和$\mathcal{S}_2$有相同的子空间,从而构建特征空间之间的桥梁。因此我们得以在$\mathcal{T}_2$阶段,通过这座桥梁来重建$\mathcal{S}_1$空间的数据。这种重构自然而然是通过变分自编码器去实现,因为前面描述的都是VAE编码的过程,重构则需要解码器。
VAE是一个多层的神经网络架构,这就来到了上文提到的第一个挑战,即深度神经网络与在线学习的矛盾。作者采取了ODL中Hedge网络的设计,充分利用神经网络多层的信息进行联合决策。
Approach
先列出方法的总优化目标:
\[\min_{f_t,\phi}\sum_{\text{HBP}}\big[\sum_{t_1,t_b}\big(\mathcal{L}_{\text{VI}}(\phi)+\mathcal{L}_{\text{REC}}(\phi)\big)+\sum_{t_b,t_2}\mathcal{L}_{\text{CLF}}(f_t,\phi) \big]\]其中$\mathcal{L}$VI是变分损失,$\mathcal{L}$REC是重构损失,$\mathcal{L}$CLF是分类器损失。注意到VAE是在$\mathcal{T}_1$和$\mathcal{T}_b$阶段训练的,而分类器是在$\mathcal{T}_b$和$\mathcal{T}_2$段训练。我们依次来讲各个损失是如何设计的。
子空间空间
首先我们来看变分损失,我们建立两个独立的VAE,在线训练:
\[\mathcal{L}_{\text{VI}}^{\{\mathcal{S}_1,\mathcal{S}_1\}}=-\mathbb{E}_{Q(\text z_t\vert\text x_t)}[\log P(\text x_t\vert\text z_t)]+KL(Q(\text z_t\vert\text x_t)\Vert P(\text z_t))\]其中对于$\mathcal{S}_1$的VAE,$t\in\mathcal{T}_1\cup\mathcal{T}_b$;对于$\mathcal{S}_2$的VAE,$t\in\mathcal{T}_b$。上式的第一项等价于最大化数据生成质量,即原始数据观测值可以从提取的潜在码中解码的可能性。让元组(Enc,Dec)表示VAE中的编码器和解码器网络,第一项鼓励$\text x_t\approx\text{Dec}(\text z_t)$,其中$\text z_t=\text{Enc}(\text x_t)$;第二项的KL散度是强迫潜在分布于标准正态分布$P$接近。
至于重构损失,它是将两个独立VAE的隐空间进行对齐:
\[\mathcal{L}_{\text{REC}}=\ell[\text x_{t_b}^{\mathcal{S}_1},\text{Dec}^{2,1}(\text z_{t_b}^{\mathcal{S}_2})]+KL\big(Q(\text z_{t_b}^{S_1}\vert\text z_{t_b}^{S_1})\Vert Q(\text z_{t_b}^{S_2}\vert\text z_{t_b}^{S_2})\big)\]其中$\text{Dec}^{2,1}$是一个解码器,从$\mathcal{S}_2$对应的VAE的隐藏表示去重构$\mathcal{S}_1$域的数据,这里笔者画了一个比原文更清楚的图:
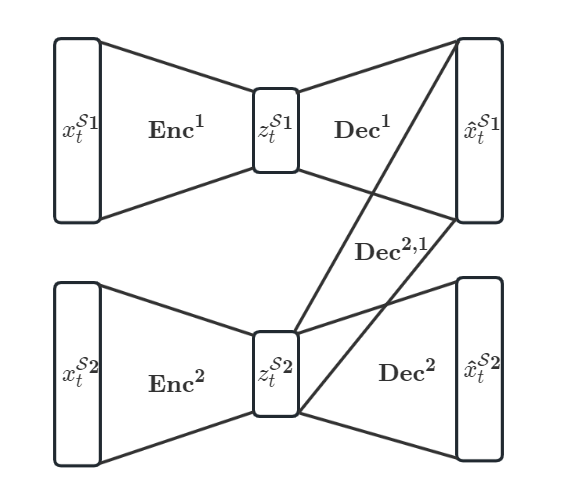
在$\mathcal{T}_b$期间,上下两个VAE都会自训练,即$\mathcal{L}$VI。而损失函数中又包括了$\mathcal{L}$REC,用于两个子空间的对齐和映射的学习。最后,我们要用的$\mathcal{S}_2\to\mathcal{S}_1$映射实际上就是$\text{Dec}^{2,1}(\text{Enc}^2(\cdot))$。
集成分类器
最后是分类损失$\mathcal{L}_{\text{CLF}}$,作者沿用了之前FESL-c的思想,用两个分类器做集成:
\[\begin{aligned} \mathcal{L}_{\text{CLF}}&=\ell(y_t,\hat{y}_t)=-\sum_{c=1}^Cy_{t,c}\log(\hat y_{t,c}),&\forall t\in\mathcal{T}_b\cup\mathcal{T}_2,\\ \hat{y}_t&=p\cdot f_t^{\mathcal{S}_1}(\tilde{x}_t^{\mathcal{S}_1})+(1-p)\cdot f_t^{\mathcal S_2}(\text x_t),&\text x_t\in\mathcal S_2, \end{aligned}\]其中$\tilde{x}_t^{\mathcal{S}_1}$就是通过上述映射复原的$\mathcal{S_1}$空间数据。其中$p$是权重参数,通过两个学习器的累积损失进行更新:
\[p=\dfrac{\exp(-\eta R_T^{\mathcal S_1})}{\exp(-\eta R_T^{\mathcal S_1})+\exp(-\eta R_T^{\mathcal S_2})}\]其中
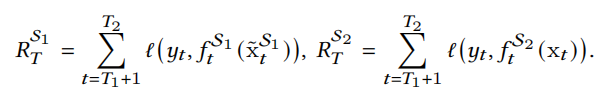
$\eta$是一个超参数。
自适应深度的网络
通过重构映射和集成预测,可以获得未观测到的$\mathcal{S}_1$所传递的信息,从而提高学习性能。剩下的问题是如何实现映射和分类器与适当深度的模型,最有可能产生最优解。不幸的是,如果没有事先知道数据流是如何在样本空间中演化的情况下,事先确定这深度是不可能的。
在这里,作者用了Hedge Backpropagation (HBP)来解决这一问题。我们在上一篇Blog中详细介绍了该方法。对于VAE每一层,都要进行上述的对齐操作,下图是原文给出的结构图:
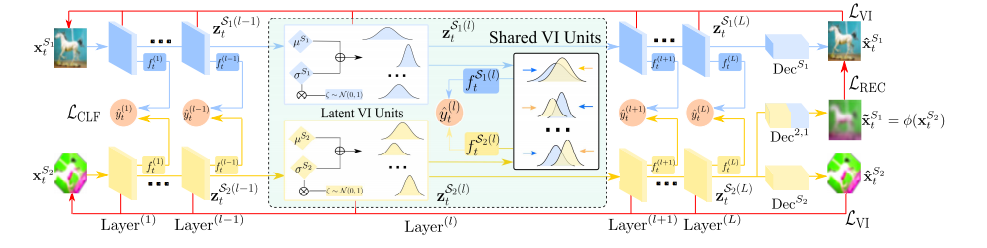
注意到每一层都会有一个两个特征空间对齐的操作(这样真的不会复杂度爆炸吗)。
实验省略
Conclusion
本文提出了一种新的在线学习范式OLD$^3$S,它使深度学习者能够在不断变化的特征空间下在数据流上做出实时决策。其关键思想是在新旧特征之间建立映射关系,一旦旧特征消失,就从新特征中重构,允许学习者获取新旧特征信息,通过集成进行准确的在线预测。要实现这一理念,关键在于模型的在线性和表现性的协调。为了尊重现实世界数据流中的高维和复杂特征相互作用,我们的OLD$^3$S方法使用变分近似发现了一个共享的潜在子空间,它可以编码任意表达的映射函数用于特征重构。同时,由于数据流的实时特性影响了浅层模型,我们的方法享有从数据中学习到的最佳深度,如果需要以在线方式捕获更复杂的模式,则从浅层开始,逐渐变得深。比较研究证明了我们的方法的可行性和它优于最先进的竞争对手。