前篇:https://welts.xyz/2022/08/12/gcn/,在那里我们介绍了基于谱域的第三代GCN,同时引出了消息传递机制。本文会介绍如何用PyTorch实现一个GCN,然后去实现图节点分类任务。
Formulation
单隐层GCN的形式化如下:
\[\text{GCN}(\hat{A},X)=f_2(\hat{A}f_1(\hat{A}XW_1)W_2)\]其中$\hat{A}$为归一化的图邻接矩阵,$X$为节点的特征向量,$f_1,f_2$为任意激活函数,$W_1,W_2$为可学习的权重矩阵。通过观察矩阵的尺寸,我们发现$W_1$和$W_2$仅与图节点的特征维数有关,这表示同一个GCN允许不同节点数的图输入。
Mission
在这里,我们将会对 Karate空手道俱乐部数据集进行图节点分类。该复杂网络是常用于复杂网络社区发现研究的网络,该网络共有 34个节点和78条边,其中34个节点表示某空手道俱乐部的 34 名成员,节点之间的边表示两个成员相互认识,该数据集是一个真实的数据集,其对应于美国的一个空手道俱乐部的人物关系的研究。
俱乐部每个成员对应一个结点,每个成员隶属于两个社区之一。我们使用NetworkX包来获取该数据,同时绘制出网络,结点颜色代表成员所属社区,即数据标签。
import networkx as nx
zkc = nx.karate_club_graph()
A = nx.to_numpy_array(zkc)
N = A.shape[0]
node_color = [['blue', 'orange'][int(zkc.nodes[i]["club"] == "Mr. Hi")]
for i in range(N)]
nx.draw(zkc, node_color=node_color)
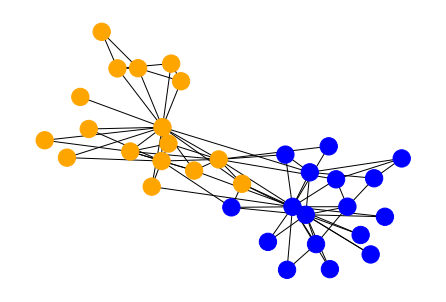
值得注意的是,该数据集的节点是没有特征的,我们只能获取到图的拓扑结构。因此,节点特征只能是独热向量,只能用来进行样本间的区分,所以特征向量矩阵$X=I$。如果将这样的$X$输入到全连接网络,训练结果只会过拟合。
图结点分类在训练的过程中,学习器必须要看见这张图上所有的结点。即使我们将数据划分成有标签的训练集结点和无标签的测试集结点,GCN训练的时候还是会用到测试集数据。因此,GCN的图节点分类是一个半监督学习任务。
GCN
现在考虑用PyTorch构建网络结构,首先是图数据的计算:
import numpy as np
import torch
A = nx.to_numpy_array(zkc)
N = A.shape[0] # 结点数
A_tilde = A + np.eye(N)
D_tilde = 1 / np.sqrt(A_tilde.sum(1))
# 通过NumPy广播计算归一化邻接矩阵,比按原公式计算更快
A_hat = np.c_[D_tilde] * D_tilde * A_tilde
X = np.eye(N) # 节点表示为独热向量
y = np.array([int(zkc.nodes[i]["club"] == "Mr. Hi") for i in range(N)]) # 标签
A_hat = torch.tensor(A_hat).float()
X = torch.tensor(X).float()
y = torch.tensor(y).long()
然后是网络的搭建等步骤,按上文的公式堆就行:
from torch import nn
from torch.optim import Adam
class GCN(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = torch.nn.Linear(N, 32, bias=False) # 隐藏层为32
self.linear2 = torch.nn.Linear(32, 2, bias=False)
def forward(self, x):
x = torch.relu(torch.matmul(A_hat, self.linear1(x)))
return torch.matmul(A_hat, self.linear2(x))
gcn = GCN()
criterion = nn.CrossEntropyLoss()
optimizer = Adam(gcn.parameters(), lr=0.05)
然后就是训练过程了,训练过程中记录损失和准确率:
# 训练测试数据集划分
n_train = int(N * 0.8)
perm = np.random.permutation(N)
train_index = perm[:n_train]
test_index = perm[n_train:]
# 记录训练测试误差和准确率
train_acc_list = []
train_loss_list = []
test_acc_list = []
test_loss_list = []
for i in range(20):
# 输入整张图
output = gcn(X)
# 针对训练集计算误差和优化
loss = criterion(output[train_index], y[train_index])
optimizer.zero_grad()
loss.backward()
optimizer.step()
pred = (output.detach().numpy().argmax(1) == y.numpy()).astype(float)
train_acc = pred[train_index].mean()
test_acc = pred[test_index].mean()
train_loss = loss.item()
test_loss = criterion(output[test_index], y[test_index]).item()
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
train_loss_list.append(train_loss)
test_loss_list.append(test_loss)
绘制出训练和测试损失和准确率:
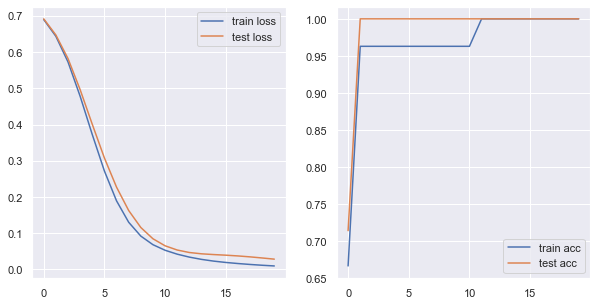
20轮训练下,训练和预测准确率都能到100%。
GCNConv Layer
在这里,我们参考PyG的GCNConv,编写自由度更高,模块化更好的GCN层。GCNConv的参数:
in_channels:输入特征数;out_channels:输出特征数;improved:如果为True,那么$\tilde{A}$的计算方式为$A+2I$,否则为$A+I$;cached:如果为True,那么$\hat{A}$的计算结果会被保留下来,仅限于 transductive learning的情形,我们上面的图节点分类就属于这种情形;add_self_loops:如果为False,那么$\tilde{A}=A$;normalize:是否要加自环和归一化;bias:是否要加偏置项。
笔者将上面的操作模块化:
class GCNConv(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
improved: bool = False,
cached: bool = False,
add_self_loops: bool = True,
normalize: bool = True,
bias: bool = True,
) -> None:
super().__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.improved = improved
self.cached = cached
self.add_self_loops = add_self_loops
self.normalize = normalize
self.linear = nn.Linear(in_channels, out_channels, bias=False)
if bias:
bound = 1 / (self.in_channels**0.5)
self.bias = nn.parameter.Parameter(torch.empty(out_channels))
nn.init.uniform_(self.bias, -bound, bound)
else:
self.bias = None
def forward(self, x: torch.tensor, edge_index: torch.tensor):
if not (hasattr(self, "coef") and self.cached):
self.coef = self.compute_coef(edge_index)
ret = self.coef @ self.linear(x)
if self.bias is not None:
ret += self.bias
return ret
def compute_coef(self, edge_index: torch.tensor):
hat_A = edge_index
if self.normalize:
if self.add_self_loops:
hat_A += torch.eye(edge_index.shape[0])
if self.improved:
hat_A += torch.eye(edge_index.shape[0])
tilde_D = 1 / torch.sqrt(torch.sum(hat_A, 1))
hat_A = tilde_D.reshape(-1, 1) * tilde_D * hat_A
return hat_A
从而编写更简单的GCN:
class GCNNew(torch.nn.Module):
def __init__(self) -> None:
super().__init__()
self.gcn1 = GCNConv(N, 16, cached=True)
self.gcn2 = GCNConv(16, 2, cached=True)
def forward(self, x, edge_index):
x = torch.relu(self.gcn1(x, edge_index))
return self.gcn2(x, edge_index)
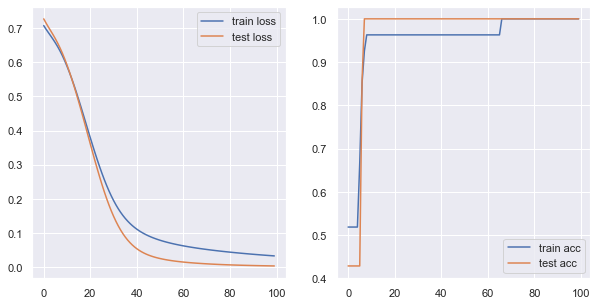
得到类似的训练效果:
Summary
我们这里实现了单隐层的GCN,并将其应用在图节点分类任务上,并获得了不错的效果。同时,我们将GCN卷积的过程仿照当前流行框架模块化,能够更方便地进行图神经网络的编写。