承接XGBoost:A Scalable Tree Boosting System(1),在讲完基本的算法后,本文将重点介绍XGBoost的系统实现。
并行学习的Column Block
树学习中最耗时的一步其实是给定数据集对某一特征进行排序。XGBoost为了节省排序时间,将数据放在被称作”块“的内存单元中。块中的数据按照列压缩格式(CSC)进行存储,且每一列都已经排序好了。这样,我们只需要在训练前排序一次,在之后的循环中复用即可。
在精确贪心算法中,我们在一个块中存储整个数据集,然后进行分割算法,也就是对排序好的数据进行线性遍历。我们对所有叶节点进行分割查找,因此只需要一次扫描,块将收集所有叶片中分割候选叶的统计数据,即梯度而二阶导数信息。论文中的示意图:
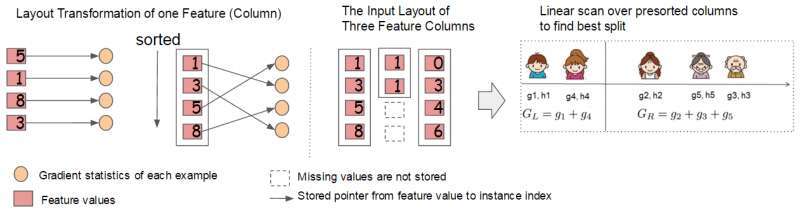
左图说的是,对于一列数据,列特征值与对应样本的统计信息通过指针一一对应,排序是对特征值的排序,但保留了其与统计信息的对应关系。‘
该方法也可以应用于近似算法。近似算法在此时需要多个块,可适用于分布式系统和多磁盘。此时就可以并行对各个块进行排序。此时分位数的查找也是一个线性遍历。计算每个列的统计数据可以并行化,为我们提供了一个拆分查找的并行算法。重要的是,列块结构还支持列子采样,因为要在块中选择列的子集很容易。
时间复杂度分析
令$d$为树的最大深度,$K$是树的数量。对于精确贪心算法,原始的稀疏感知算法的时间复杂度为$O(Kd\Vert\pmb{x}\Vert_0\log n)$。另一方面,提升树在块结构上的时间复杂度只有$O(Kd\Vert{\pmb x}\Vert_0+\Vert{\pmb x}\Vert_0\log n)$。后一项是可以均摊的一次性预处理成本。当$n$很大的时候,块结构的应用可以大幅度减少算法时间。
对于近似算法,原始的时间复杂度为$O(Kd\Vert\pmb x\Vert_0\log q)$,其中$q$是在数据集上预计的候选划分个数,通常选$32$到$100$之间。而块结构能将时间复杂度降到$O(kd\Vert\pmb x\Vert_0+\Vert x\Vert_0\log B)$,其中$B$是每个块的最大数据行数。同样,块结构可以削减掉时间复杂度中的$q$。
缓存感知方法
虽然前面提出的块结构有助于优化分割查找的计算复杂度,但新的算法需要通过行索引间接获取梯度统计量,因为这些值是按特征的顺序访问的。这是一个非连续的内存访问。拆分枚举的一种简单实现就是引入累积和非连续内存读取操作之间的即时读/写依赖关系(似乎就是缓存)。如下图所示
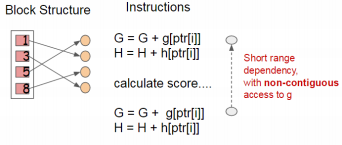
如果对应的梯度信息没有进入CPU时(也就是Cache Missing),这样就会令分割查找的进程缓慢下来。
对于精确的贪婪算法,我们可以通过一个高速缓存感知的预取算法来缓解这个问题。具体来说,我们在每个线程中分配一个内部缓冲区,将梯度统计信息获取到其中,然后以小批处理的方式累积。这种预取将直接读/写依赖关系更改为更长的依赖关系,并有助于行数较大时减少运行时开销。
对于近似算法,我们通过选择一个正确的块大小来解决这个问题。我们将块的大小定义为块中包含的数据instance的最大数量,因为这反映了梯度统计数据的缓存存储成本。选择过小的块大小会导致每个线程的工作负载较小,并导致低效率的并行化。另一方面,过大的块会导致缓存丢失,因为梯度统计数据不适合于CPU缓存。一个好的块大小会选择平衡这两个因素。作者通过实验得出$2^{16}$个样本/块是缓存和并行两个因素的trade-off。
核外计算的块
我们系统的目标之一是充分利用机器的资源来实现可扩展的学习。除了处理器和内存之外,利用磁盘空间来处理未进入主存的数据(原因常常是数据太大)也是很重要的。为了实现核心外计算,我们将数据分成多个块,并将每个块存储在磁盘上。在计算过程中,使用一个独立的线程将块预取到一个主存缓冲区中是很重要的,因此计算可以与磁盘读取同时进行。然而,这并不能完全解决这个问题,因为磁盘读取需要花费大部分的计算时间。降低开销和提高磁盘IO的吞吐量非常重要。我们主要使用两种技术来改进核外计算。
- 块压缩:块被列压缩,并在加载到主存时由一个独立的线程动态解压缩。这有助于将解压中的一些计算与磁盘读取成本进行交换。我们使用一种通用的压缩算法来压缩特征值。对于行索引,它减去块的初始索引,得到一个偏移量,并使用一个16位的整数来存储每个偏移量。这需要每个块$2^{16}$个示例,前面说过这是一个好的设置。在实验测试的大多数数据集中,作者实现了大约26%到29%的压缩比。
- 块分区:将数据分割到多个磁盘上。为每个磁盘分配一个预抓取线程,并将数据提取到内存缓冲区中。然后,训练线程会交替地从每个缓冲区中读取数据。这有助于在有多个磁盘可用时提高磁盘读取的吞吐量。
总结
文章到这里就大体上结束了,后面是一些总结和实验结果,这里不过多介绍,有兴趣的读者可以阅读原文。
论文描述了作者在构建XGBoost时获得的经验,这是一个可扩展的树增强系统,被数据科学家广泛使用,并在许多问题上提供了最先进的结果。我们提出了一种新的稀疏感知算法处理稀疏数据和理论证明的加权分位数略图近似学习。我们的经验表明,缓存访问模式、数据压缩和分区是构建一个可伸缩的端到端树提升系统的基本元素。这些经验也可以应用于其他机器学习系统。通过结合这些见解,XGBoost能够使用最少的资源解决现实世界规模问题。