引言
用训练集训练一个决策树(ID3、C4.5、CART)模型后,可能会产生过拟合,这是由树结构本身的性质决定的。因此“剪枝”操作往往是必要的。在周志华老师的《机器学习》中,提到了“预剪枝”和“后剪枝”,在笔者使用模型和阅读资料后,发现剪枝策略远比这两种剪枝复杂得多,本文便是对剪枝策略的一个综述。
预剪枝
在《机器学习》中,预剪枝是在生成分支的同时,用验证集进行测试,如果产生分支前的决策树比分支后在验证集上反而有更好的精度,那么我们不会接受这一分支操作。
实际上,预剪枝的方法还有很多,比如在sklearn.tree.DecisionTreeClassifier的函数参数中,我们可以见到更多的预剪枝手段:
max_depth:限制决策树的最大深度;min_samples_split:如果某一节点包含的训练样本太少,则不会进行分支;min_samples_leaf:限制叶子节点包含样本的数目;min_impurity_decrease:如果不纯度下降幅度小于一定程度,则停止分支;- $\cdots$
相比于使用验证集,上面这些预剪枝更加简单方便。预剪枝基于“贪心”禁止了一些本可能是“好”的分支,决策树因此会有欠拟合的风险。
后剪枝
后剪枝是在生成了一个完整的决策树后,对其进行剪枝。在《机器学习》中,决策树的后剪枝也是使用一个验证集,自下而上地比较剪枝与不剪枝的精度差,如果剪枝的性能好(或相等,根据奥卡姆剃刀原则),就去剪枝。这一剪枝方法也被称作REP(Reduced Error Pruning,错误率降低剪枝)。
我们在这里介绍其他几种可用的剪枝算法。
MEP(minimum error pruning)
MEP方法也是计算剪枝前和剪枝后的精度差,但用的不是验证集而是原训练集。如果不加处理地比较剪枝前后的误差,根据决策树的分支算法,剪枝后的决策树在训练集上的误差肯定比剪枝前要高。因此,MEP采用的是将每个分支的误差加权相加,权重为对应分支中训练样本的比例。计算误差$E$:
\[E(t)=\dfrac{n(t)-n_c(t)+(k-1)}{n(t)+k}\]对于一节点$t$,$n(t)$为$t$中的样本总数,$n_c(t)$为$t$中主类的样本数目,$k$为类个数。对于自下而上的剪枝来说,设$T_t$为节点$t$为根节点的子树叶节点,那么如果
\[E(t)>\sum E(T_t)\]则保留该子树,否则就剪枝。
PEP(Pessimistic-Error Pruning)
知识基础:二项分布的连续性校正。
悲观剪枝是由决策树的提出者罗斯·昆兰提出的一种剪枝算法,和上面一样,也只需要原训练集即可。他认为显式的错误率(Apparent error rate),也就是训练集上的错误率,是一种乐观的估计,不适合作为剪枝的依据。因此昆兰引入了二项分布的连续性校正来获取一个更加现实(悲观)的错误率,这也是“悲观剪枝”名称的由来。
This pruning method, proposed by Quinlan, like the previous one, is characterized by the fact that the same training set is used for both growing and pruning a tree. Obviously, the apparent error rate, that is the error rate on the training set, is optimistically biased and cannot be used to choose the best pruned tree. For this reason, Quinlan introduces the continuity correction for the binomial distribution that might provide “a more realistic error rate.”
——《A Comparative Analysis of Methods for Pruning Decision Trees》
我的理解:对于一个二叉决策树(连续变量的C4.5决策树,CART决策树)最深的决策节点(即其子节点全部为叶节点),就像下图这种结构
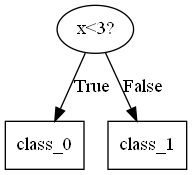
由于子节点的标签是由落到该节点的训练样本中占比最大的类别决定,因此必然存在误分。子节点中误分类的样本个数满足二项分布,而一般的误差符合正态分布,根据中心极限定理,$n$极大时二项分布会逼近一个同均值同方差的正态分布,而在计算累积概率密度的时候,由于离散求和和连续积分的原理差异,我们需要用一个校正项0.5进行连续性校正,确保结果的相近。因此,对于一个节点,其显式的误分率:
\[r(t)=\dfrac{e(t)}{n(t)}\]也就是误分样本数除以落在该节点的样本数,然后我们对误差进行连续性校正,得到该节点修正误差
\[r'(t)=\dfrac{e(t)+0.5}{n(t)}\]对于一个待剪枝的节点$t$,其子节点总的修正误差和也不难计算
\[r'(T_t)=\dfrac{\sum_{t\in T_t} e(t)+0.5\vert T_t\vert}{\sum_{t\in T_t}n(t)}\]$T_t$为节点$t$的所有叶节点。然后估计误差(不是误差率,误差是上式的分子)的最坏情况(悲观),也就是正态分布中误差最大的情况:
\[\text{pessimistic_error}=\text{error}+\text{std}\]只要剪枝后的修正误差不大于上面的悲观误差,就可以进行剪枝。我们来举个例子:以上面的子树为例,假设在$x<3$节点中,落在该节点的样本有10个,其中6个0类,4个1类;经过判断,落在左边子节点的0类样本4个,1类样本1个;右子节点的0类样本2个,1类样本3个:
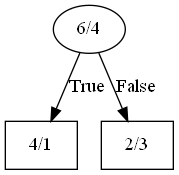
根据多数原则,左子节点的标签为0,右边为1。根据上面的计算方法,我们得到左右子节点的修正误分率:
\[r_{\text{left}}'=\frac{1+0.5}{5}=0.3,r_{\text{right}}'=\frac{2+0.5}{5}=0.5\]所有子节点的误差率和:
\[r'(T_t)=\frac{1+0.5+2+0.5}{1+4+2+3}=0.4\]误差和就是上式的分子,也就是4。计算二项分布标准差:
\[\text{std}=\sqrt{np(1-p)}=\sqrt{10\times 0.4\times 0.6}=1.55\]得到悲观误差:
\[\text{pessimistic_error}=4+1.55=5.55\]然后模拟剪枝,即减掉两个叶子节点,决策节点作为新的叶节点:6个0类,4个1类,因此标签为0类,其修正误差为
\[\dfrac{4}{6+4}\times (6+4)=4<5.55\]由于剪枝后的修正误差小于悲观误差,因此我们可以进行剪枝。
我们在https://github.com/Kaslanarian/PythonDecisionTree实现了C4.5决策树的剪枝算法,对于鸢尾花数据集,直接训练的决策树是下面这样的:
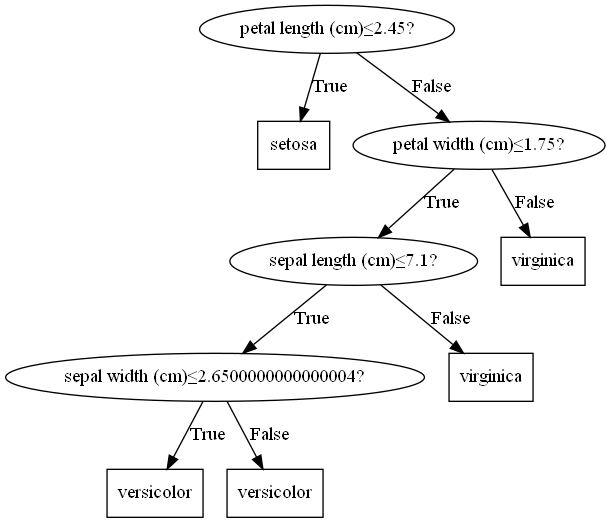
而经过了PEP剪枝,决策树被剪成
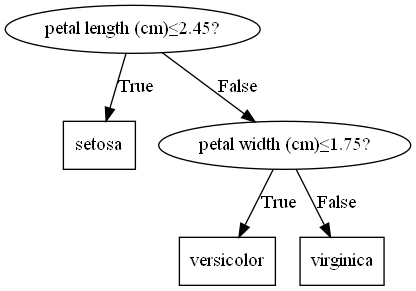
决策树更加简洁,而且泛化测试误差得到了提升($97.78\%\to100\%$)。
CCP(Cost Complexity Pruning)
CCP,也就是基于代价复杂度的剪枝,是一种自下而上后剪枝算法,在CART决策树中被使用。CCP算法将初始的未剪枝决策树设置为$T_0$,从其底端不断剪枝,直到决策树的根节点。这会形成一系列的子树序列$\{T_0,T_1,\cdots,T_n\}$。在这一决策树序列中,通过在验证集上测试,选出最优子树。
子树序列的生成
我们定义决策树子树$T$的损失函数(经验风险+结构风险):
\[C_\alpha(T)=C(T)+\alpha\vert T\vert\]经验风险就是$C(T)$,对训练数据的预测误差;$\vert T\vert$为子树的叶节点个数,$\alpha\geq0$为参数。
我们选择未剪枝决策树$T_0$的一个内部节点(即非叶节点)$t$,如果对其进行剪枝,那么对应的损失函数为
\[C_\alpha(t)=C(t)+\alpha\]而如果不剪枝,以$t$为根节点的子树$T_t$的损失函数为
\[C_\alpha(T_t)=C(T_t)+\alpha\vert T_t\vert\]我们设
\[f(\alpha)=C_\alpha(t)-C_\alpha(T_t)\]我们有
\[\begin{aligned} f(0)&=C(t)-C(T_t)>0\\ f(+\infty)&=\alpha(1-\vert T_t\vert)+C(t)-C(T_t)\to-\infty \end{aligned}\]$f$是连续函数,根据零点定理,必然存在一$\alpha>0$,满足
\[f(\alpha)=0\]我们也不难解出
\[\alpha=\dfrac{C(t)-C(T_t)}{\vert T_t\vert-1}\]在$\alpha$为该值时,剪枝前和剪枝后的损失函数相同,根据奥卡姆剃刀原则,我们选择剪枝。而且,当$\alpha$大于该值时,剪枝总比不剪枝好。这样的关系是递归的:当$\alpha$更大时,我们就需要第二次剪枝,剪枝两次的损失函数就会小于一次剪枝的损失函数
\[\begin{cases} \alpha\lt\alpha_0&不剪枝最优\\ \alpha_0\leq\alpha\lt\alpha_1&剪枝一次最优\\ \alpha_1\leq\alpha\lt\alpha_2&剪枝两次最优\\ \cdots \end{cases}\]Breiman等人证明,将$\alpha$从小增大,$0\lt\alpha_0\lt\alpha_1\lt\cdots\lt\alpha_n\leq+\infty$,这样就产生了n+1个区间:$[\alpha_i,\alpha_{i+1}),i=1,\cdots,n$和$[\alpha_n,+\infty)$。其实是对应了前面提到的子树序列,$\{T_0,\cdots,T_n\}$,其在对应区间上是最优的。
我们给出CCP剪枝算法:
def CCPruning(T0, valid_X, valid_y) -> Tbest:
'''
用CCP剪枝生成最优决策树
parameters
----------
T0 : 未剪枝决策树
valid_X : 验证数据集
valid_y : 验证标签集
return
------
Tbest : 最优决策树
'''
k = 0
T = T0
tree_list = [T0]
while True: # 生成子树序列
alpha = inf
for internal node t in T0: # 对内部节点以自下而上的顺序遍历
calcuate C(T_t), |T_t|
g(t) = (C(t) - C(T_t)) / (|T_t| - 1)
alpha = min(alpha, g(t))
for internal node t in T0:
if g(t) == alpha:
prune t # 如果g(t)=alpha,则对该内部节点剪枝
k = k + 1
alpha_k = alpha
T_k = T
if T_k is a root with 2 leaves:
# 如果T_k是由根节点和两个叶节点构成的树,则退出循环
T_k = T_n
break
tree_list.append(T_k)
score_list = []
for tree in tree_list:
score = tree.score(valid_X, valid_y) # 用验证集训练测试
score_list.append(score)
max_perf = max(score_list)
best_tree = tree_list[score_list.index(max_perf)] # 选择最优树
return best_tree
当然我们也可以不用验证集进行交叉验证,我们只需要自己设置一个ccp_alpha,自下而上剪枝,直到待剪枝节点的$\alpha$超过了ccp_alpha便停止剪枝。