引言
libSVM总体由头文件svm.h和源文件svm.cpp构成,我们在这里对libSVM的总体结构和svm.h数据结构进行剖析。
libSVM结构
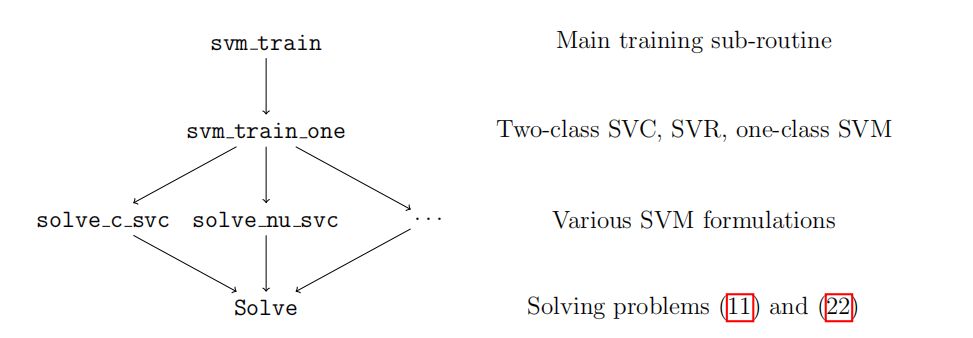
如图是libSVM求解问题的逻辑结构:训练一个复杂的SVM模型,也就是svm_train,实际上以训练一个支持向量机为基础的(svm_train),我们提到过libSVM中可以求解5种SVM模型。所以svm_train会选择一个SVM进行求解,比如solve_c_svc便是求解SVM分类问题;但所有的支持向量机最终都是解决一个线性约束的二次规划问题,因此万流归宗,所有问题都要用Solve函数求解。
数据结构共四种:
svm_node:数据节点;svm_proble:数据集;svm_parameter:SVM参数;svm_model:SVM模型;
类结构有两种:
- 用于存储核函数的
QMatrix类; - 用于求解规划问题的
Solver类.
头文件:svm.h
数据结构
在头文件中有一些结构体被定义,第一个structure:
struct svm_node {
int index;
double value;
};
这个结构体表示一个数据单位,比如我们用下面的代码
svm_node data[] = {
{1, 0.12};
{2, 1.40};
{3, 4.00};
{-1};
}
就构建一条这样的数据:
| 1 | 2 | 3 | -1 |
|---|---|---|---|
| 0.12 | 1.40 | 4.00 | 空 |
也就是$\pmb x_i=(0.12,1.40,4.00)$。之所以使用了index,是为了在大量数据为0时节省存储空间,比如下面的代码
svm_node data[] = {
{1, 0.12};
{2, 1.40};
{4, 4.00};
{-1};
}
创建的数据为$\pmb x_i=(0.12,1.40,0,4.00)$;还有一个好处就是在做点乘的时候可以加快运算速度。
第二个structure:
struct svm_problem {
int l;
double *y;
struct svm_node **x;
};
这个结构体表示数据集:l为数据集的数据量;y对应分类问题中的标签,或者是回归问题中的输出;而x就是特征向量,一个指向指针的指针,存储的是二维表格数据:x[0]就是数据集第一条数据,x[0][0].value就是第一条数据的第x[0][0].index个数据。示意图如下:
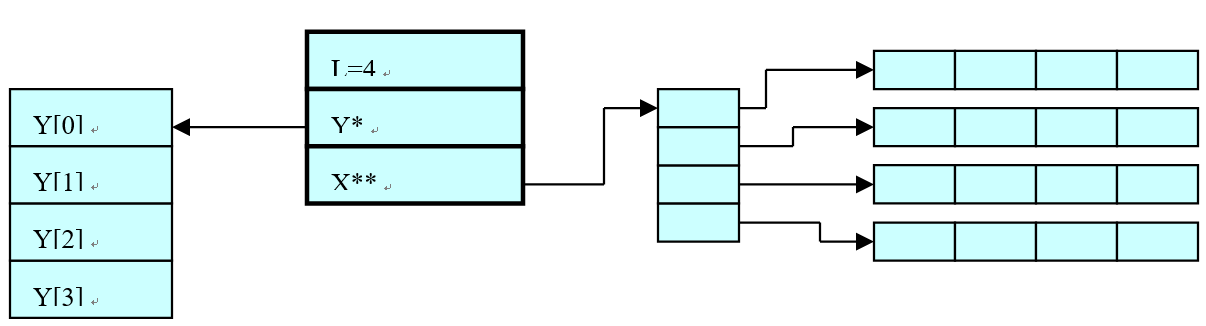
对应样本数为4的数据集。
第三个structure:
enum { C_SVC, NU_SVC, ONE_CLASS, EPSILON_SVR, NU_SVR }; /* svm_type */
enum { LINEAR, POLY, RBF, SIGMOID, PRECOMPUTED }; /* kernel_type */
struct svm_parameter {
int svm_type;
int kernel_type;
int degree; /* for poly */
double gamma; /* for poly/rbf/sigmoid */
double coef0; /* for poly/sigmoid */
/* these are for training only */
double cache_size; /* in MB */
double eps; /* stopping criteria */
double C; /* for C_SVC, EPSILON_SVR and NU_SVR */
int nr_weight; /* for C_SVC */
int *weight_label; /* for C_SVC */
double *weight; /* for C_SVC */
double nu; /* for NU_SVC, ONE_CLASS, and NU_SVR */
double p; /* for EPSILON_SVR */
int shrinking; /* use the shrinking heuristics */
int probability; /* do probability estimates */
};
这是一个SVM模型的参数,从变量命名和注释不难看出各个成员变量的含义:
-
svm_type:支持向量机类别,对应不同的学习任务; -
kernel_type:使用哪种核方法,有线性核、多项式核、RBF核(高斯核)、Sigmoid核等;对应的核函数公式:
\[\begin{aligned} K_{\text{linear}}(\pmb x_i,\pmb x_j)&=\pmb x_i^\top\pmb x_j\\ K_{\text{poly}}(\pmb x_i,\pmb x_j)&=(\gamma\pmb x_i^\top\pmb x_j+r)^d\\ K_{\text{RBF}}(\pmb x_i,\pmb x_j)&=\exp(-\gamma\Vert\pmb x_i-\pmb x_j\Vert^2)\\ K_{\text{Sigmoid}}(\pmb x_i,\pmb x_j)&=\tanh(\gamma\pmb x_i^\top\pmb x_j+r)\\ \end{aligned}\] -
degree:对应多项式核的$d$; -
gamma:对应上面核函数公式的$\gamma$; -
coef0:对应公式中的$r$.
下面则是训练过程中需要的参数:
-
cache_size:用于存放数据所需的内存空间,以MB为单位; -
\[m(\pmb\alpha^k)-M(\pmb\alpha^k)\le\varepsilon\]eps:对应工作集选取时用到的容忍值$\varepsilon$:则认为$\pmb\alpha^k$已经是最优解;
-
C,惩罚因子$C$; -
nr_weight:直译是“权重的数目”,具体含义不明; -
weight_label:同上,感觉和上面相关; -
nu:对应$\nu$-SVC和$\nu$-SVR中的参数$\nu$; -
p:不明; -
shrinking:决定训练过程中是否使用Shrinking技巧; -
probability:指明训练过程是否需要预报概率.
最后一个structure是关于SVM的模型参数:
struct svm_model {
struct svm_parameter param; /* parameter */
int nr_class; /* number of classes, = 2 in regression/one class svm */
int l; /* total #SV */
struct svm_node **SV; /* SVs (SV[l]) */
double **sv_coef; /* coefficients for SVs in decision functions
(sv_coef[k-1][l]) */
double *rho; /* constants in decision functions (rho[k*(k-1)/2]) */
double *probA; /* pariwise probability information */
double *probB;
int *sv_indices; /* sv_indices[0,...,nSV-1] are values in
[1,...,num_traning_data] to indicate SVs in the training
set */
/* for classification only */
int *label; /* label of each class (label[k]) */
int *nSV; /* number of SVs for each class (nSV[k]) */
/* nSV[0] + nSV[1] + ... + nSV[k-1] = l */
/* XXX */
int free_sv; /* 1 if svm_model is created by svm_load_model*/
/* 0 if svm_model is created by svm_train */
};
大部分参数含义不难理解:
param:模型参数,有趣的是它并不是指针形式,一个可能的原因是防止下次训练将参数冲掉;nr_class:分类问题的类别数;l:支持向量个数;SV:所有的支持向量;sv_coef:支持向量在决策函数的系数,也就是$\pmb\alpha$;rho:对应$\nu$-SVC和One-class SVM中的$\rho$,它和其他问题的决策函数中的$b$互为相反数:$b=-\rho$;probA\probB:应该对应的是$r_{ij}$,具体不明;sv_indices:$\alpha_i$对应的数据$x_i$构成的数组,共l个;
以下参数仅用于分类任务中:
label:标签数组;nSV:每一类样本中支持向量个数,共nr_class个元素;free_SV:如果该模型是由svm_load_model导入,free_SV为1;如果是训练出来的,free_SV为0.
接口函数
svm.h中的接口函数有19个,但功能只有6种:
- 机器学习相关:
svm_train、svm_cross_validation; - 模型的存取:
svm_save_model和svm_load_model; - 获取模型参数:
svm_get...都是这类; - 利用模型预测:
svm_predict_...; - 模型删除和内存释放:
svm_free_model_content、svm_free_and_destroy_model和svm_destroy_param; - 调试功能接口:
svm_check...和svm_set_print_string_function.
总结
svm.h的内容就是上面这些,svm.h为用户展现了libSVM的基本框架,同时提供主要的SVM功能相关接口,但对我们来说这是不够的,我们还是需要深入svm.cpp中去理解算法细节。